Inside the Engine: How NoSQL Optimizes for Massive Writes
Search for a command to run...
No comments yet. Be the first to comment.
What is a Peer and How Do They Connect? So when we talk about conference apps like Zoom, Google Meet, or WhatsApp group calls, we're essentially talking about multiple devices connecting to each other in real-time. Each device is called a peer. A pee...
If you have multiple GitHub accounts, it can be a challenge to manage them on the same computer. Fortunately, with a few configuration changes, you can easily use multiple GitHub accounts. Here are the steps to set up multiple GitHub accounts: This g...

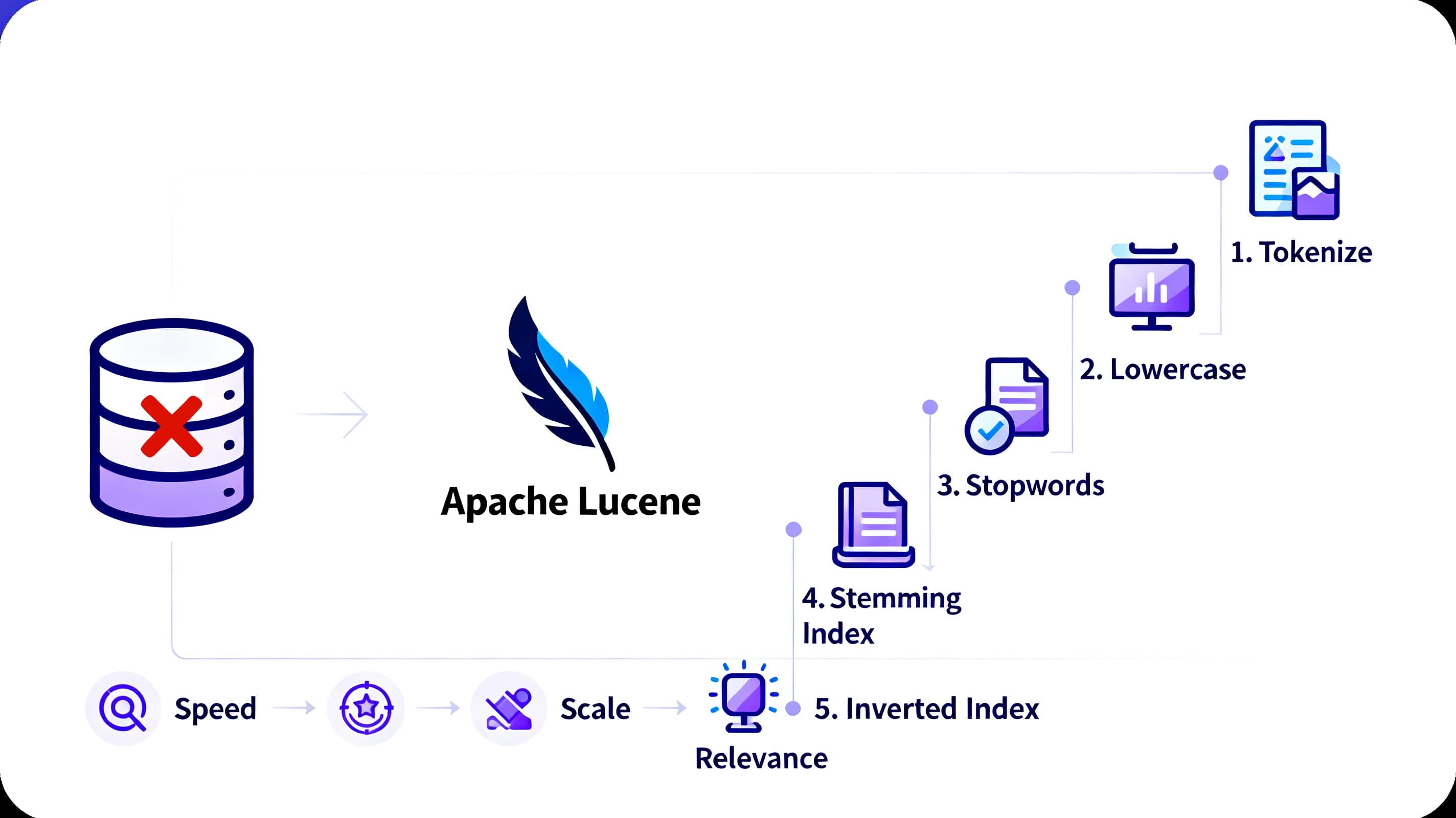
Today, I want to talk about something really cool: how Apache Lucene stores and retrieves data so efficiently. We're not diving into Elasticsearch (it's built on top of Apache Lucene) but into the magic that makes Lucene so powerful for full-text se...
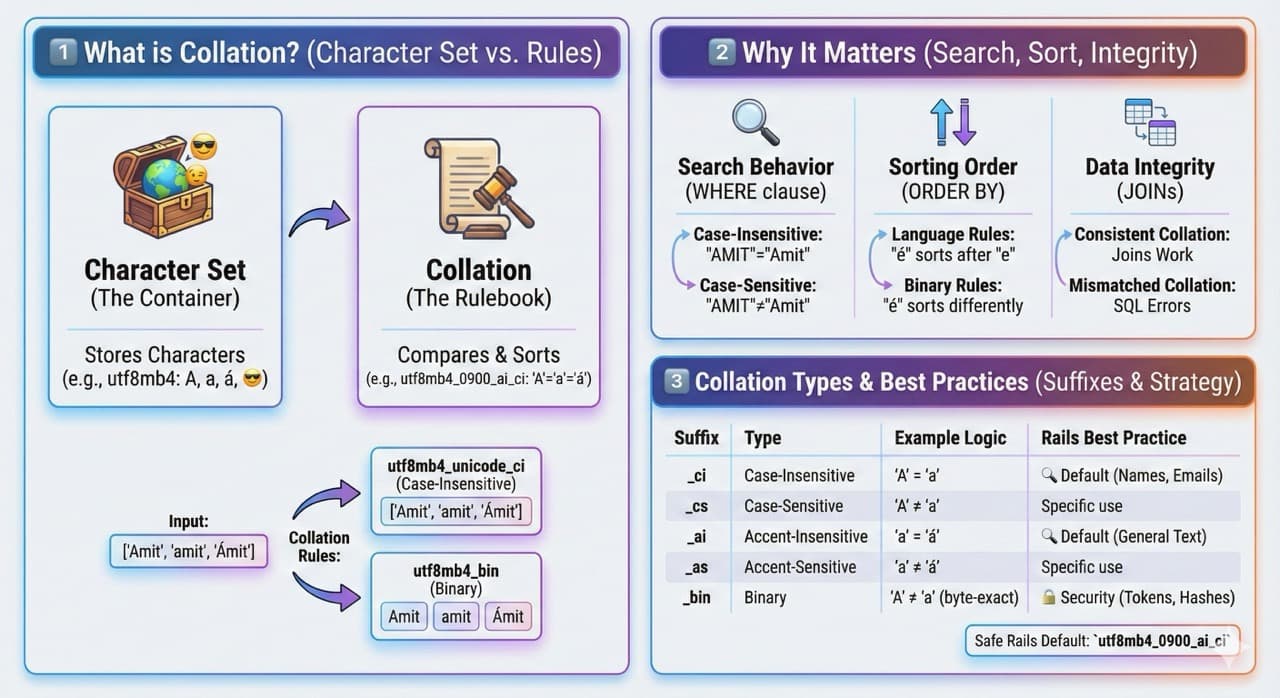
You've likely seen collation settings in your schema.rb or database.yml many times, but do you know exactly how they impact your application? In a standard Rails application, you might see this in a migration: add_column :users, :name, :string, colla...
ClearYourDoubt
5 posts
Most developers have a mental model of how a database works: You insert a row, the database finds the right spot on the hard drive (usually using a B-Tree), and slots it in perfectly. It’s neat, organized, and reliable.
But what happens when you need to handle 10 million writes per second?
At that scale, the "neat and organized" B-Tree falls apart. The constant disk seeking and rebalancing would bring your server to its knees.
Enter the LSM Tree (Log-Structured Merge Tree)—the engine under the hood of Cassandra, RocksDB, and HBase. It achieves speed by doing something that sounds counter-intuitive: It stops trying to be organized on disk immediately.
Here is how the magic works.
To make writes instant, NoSQL databases adopt a simple philosophy: Never modify a file. Always append.
Imagine keeping a diary. If you wanted to change an entry from last Tuesday, you wouldn't get an eraser, find the page, and scrub it out. You’d just write a new entry today saying, "Update regarding last Tuesday..."
This is Sequential I/O, and disks love it. It is orders of magnitude faster than hopping around the disk (Random I/O) to update old records.
# The "Lazy" Write
# Instead of finding a specific index on disk, we just tack it to the end.
def simple_append(key, value)
timestamp = Time.now.to_i
entry = "#{timestamp}:#{key}:#{value}\n"
# 'a' mode opens the file for appending, ensuring O(1) write speed
File.open('database.log', 'a') do |file|
file.write(entry)
end
end
But if we just dump data into a file, reading it back becomes a nightmare. We’d have to scan the whole file to find anything. We need a compromise.
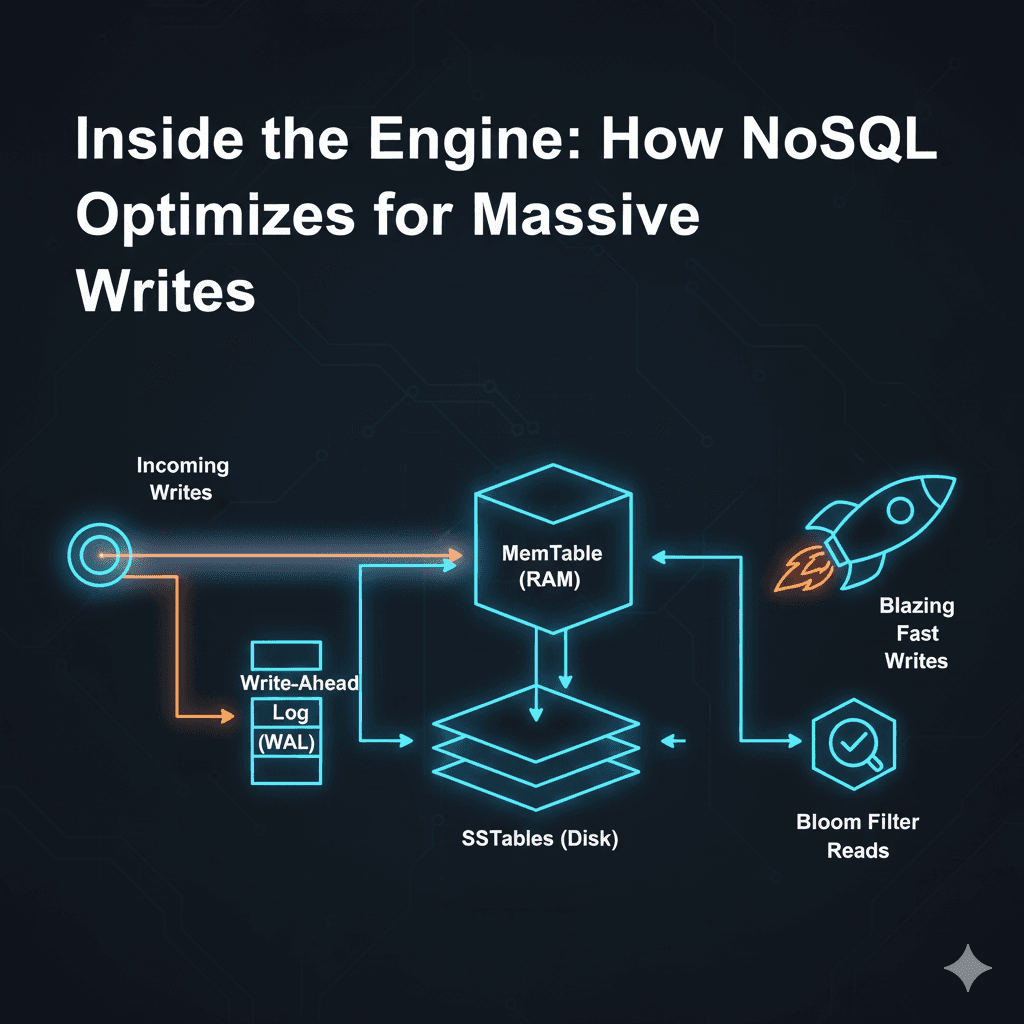
The LSM Tree uses a dual-layer approach. It treats Memory (RAM) as the staging area and Disk as the permanent archive.


When a write request hits your database, it doesn't touch the hard drive yet. It goes straight into the MemTable (Memory Table).
What is it? A sorted data structure (like a Red-Black Tree or Skip List) living entirely in RAM.
Why? Because RAM is lightning fast. We can insert and sort data here in microseconds.
# Inside the Database Engine
class MemTable
def initialize
# In a real DB, this would be a Red-Black Tree or Skip List
# to keep keys sorted automatically.
@data = {}
end
def put(key, value)
# O(log N) insert speed because we are in RAM
@data[key] = value
end
def get(key)
@data[key]
end
end
Once the MemTable gets full (say, it hits 64MB), the database freezes it. It flushes the entire sorted list to the disk in one go.
This file is called an SSTable (Sorted String Table).

Now we have a problem. We have data scattered across RAM and multiple immutable files on disk. How do we find "User: 123" without opening every single file?
We cheat. We don't create an index for every key. We create a Sparse Index.
Imagine an encyclopedia. You don't have a bookmark for every word. You have a guide that says "Aardvark starts on page 1, Apple starts on page 50."
Because our SSTables are sorted, we only need to store the offset of the first key of every 64KB block.

# We don't store every key. We only store the "signposts".
sparse_index = [
{ key: "ID-001", offset: 0 }, # Start of Block 1
{ key: "ID-500", offset: 65536 }, # Start of Block 2
{ key: "ID-900", offset: 131072 } # Start of Block 3
]
def find_block_for(target_key, index)
# If we want ID-750, we know it MUST be in Block 2
# because 750 is between 500 and 900.
candidate_block = index.select { |entry| entry[:key] <= target_key }.last
return candidate_block ? candidate_block[:offset] : nil
end
If you are looking for ID-250, and the index says ID-001 is at Block A and ID-500 is at Block B, you know for a fact that ID-250 must be in Block A.
We load just that small block, scan it, and find our data.
The architecture above is fast, but it creates some unique engineering challenges. Here is how NoSQL solves them.
If we can't edit the file, how do we delete a row?
We don't.
We write a Tombstone.
A Tombstone is a new record that literally says: "ID-123 is dead."
TOMBSTONE = "##DELETED##"
def delete_key(key)
# We don't delete. We write a new record marking it as dead.
# This is treated exactly like a normal Write operation.
@db.write(key, TOMBSTONE)
end
When the database reads data, it sees the Tombstone in the recent file and ignores any older versions of ID-123 found in older files. It shadows the old data until it's eventually cleaned up.
The MemTable is in RAM. If the power plug is pulled, that data is gone forever.
To prevent this, we use a WAL (Write-Ahead Log).
Every write is simultaneously appended to a "dumb" log file on disk before it hits memory. We never read this file—unless the server crashes. On reboot, the database replays the WAL to reconstruct the MemTable. It’s the "Black Box" flight recorder of the database.
def robust_write(key, value)
# 1. Safety First: Write to disk log
@wal.append(key, value)
# 2. Speed Second: Write to Memory
@mem_table.put(key, value)
end
The most expensive query in an LSM Tree is looking for a key that doesn't exist.
The database checks the MemTable (Miss). Then the newest SSTable (Miss). Then the next one (Miss)... all the way to the oldest file. You might scan 50 files just to realized the data isn't there.
To stop this wasted effort, we use Bloom Filters.

A Bloom Filter is a space-efficient probabilistic data structure. Think of it as a very smart, very small memory bit-array.
How it works:
Multiple Hashes: When you write a key (e.g., "ID-123"), the system runs it through multiple hash functions.
Bit Flipping: Each hash function points to a specific bit in an array, and we flip those bits to 1.
The Check: When you want to read "ID-123", we run the hashes again. If ALL the corresponding bits are 1, the key might exist. If ANY bit is 0, the key definitely does not exist.
This gives us two powerful guarantees:
False Negatives are Impossible: If the filter says "No", the data is absolutely not there.
False Positives are Possible: It might say "Maybe", but the key isn't actually there (rare, but possible).
class BloomFilter
def initialize(size)
@bit_array = Array.new(size, 0)
end
def add(key)
# Hash the key multiple times and flip bits to 1
indices = hash_functions(key)
indices.each { |i| @bit_array[i] = 1 }
end
def might_contain?(key)
indices = hash_functions(key)
# If ANY bit is 0, the key is definitely not here.
# We can skip the expensive disk read!
return false if indices.any? { |i| @bit_array[i] == 0 }
return true # It might be here, go check the disk.
end
end
def read_with_optimization(key)
# 1. Check RAM
return @mem_table.get(key) if @mem_table.contains?(key)
# 2. Ask the Bouncer (Bloom Filter)
unless @bloom_filter.might_contain?(key)
return "Key Definitely Not Found" # We skip the disk entirely!
end
# 3. Only check disk if the Bloom Filter says "Maybe"
return check_sstables_on_disk(key)
end
This simple trick saves massive amounts of I/O for missing keys.
Over time, you might have 1,000 SSTables, and ID-123 might exist in 50 of them (49 updates and 1 current value).
A background process called Compaction runs quietly. It wakes up, merges the 1,000 files into 100 larger files, tosses out the duplicates and Tombstones, and goes back to sleep.
NoSQL systems aren't magic; they are a masterclass in tradeoffs. By accepting that files should be immutable and RAM should be the primary workspace, they achieve write speeds that traditional databases can't touch.
The Recipe for Speed:
Append Only: Never seek, just write.
MemTable: Sort in RAM first.
Tombstones: Don't delete, just mark as dead.
Bloom Filters: Use math to avoid searching for what isn't there.