How Apache Lucene Makes Searching Super Fast
Search for a command to run...
No comments yet. Be the first to comment.
What is a Peer and How Do They Connect? So when we talk about conference apps like Zoom, Google Meet, or WhatsApp group calls, we're essentially talking about multiple devices connecting to each other in real-time. Each device is called a peer. A pee...
If you have multiple GitHub accounts, it can be a challenge to manage them on the same computer. Fortunately, with a few configuration changes, you can easily use multiple GitHub accounts. Here are the steps to set up multiple GitHub accounts: This g...

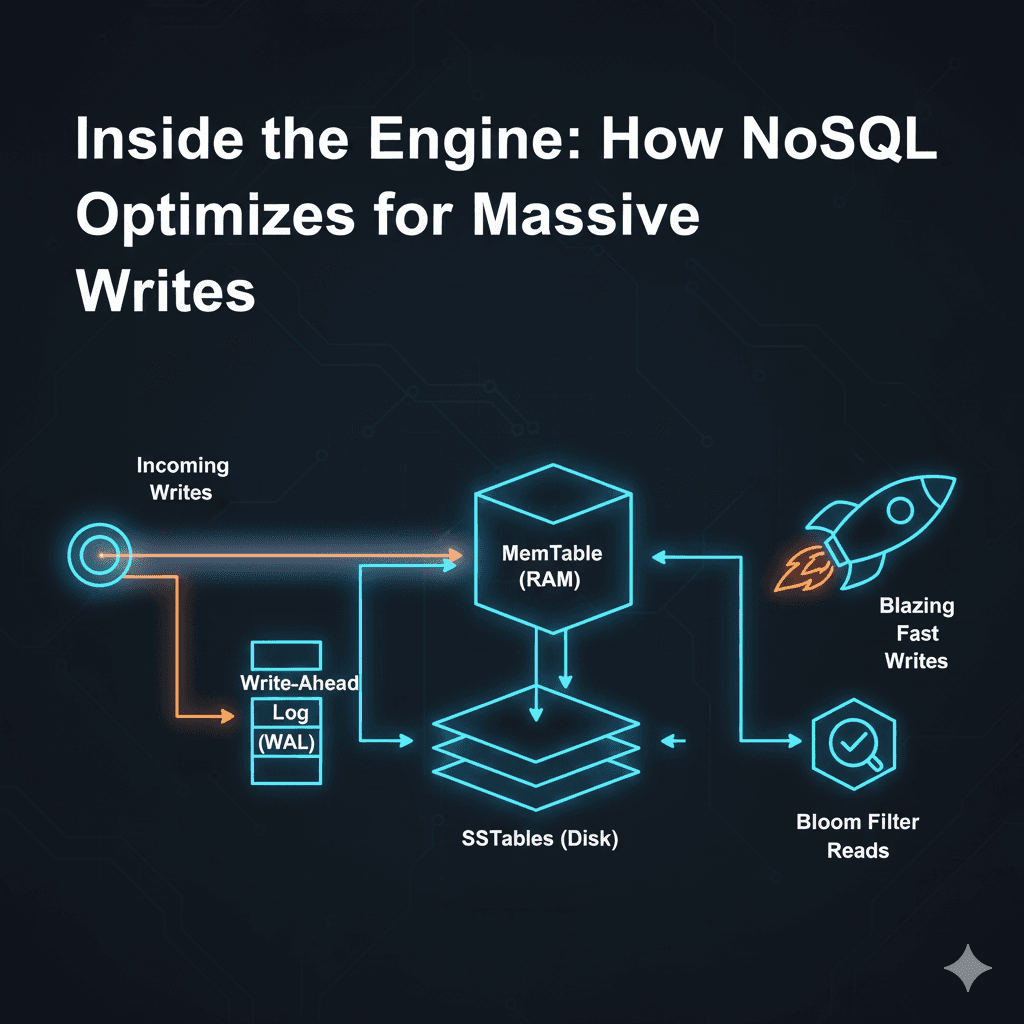
Most developers have a mental model of how a database works: You insert a row, the database finds the right spot on the hard drive (usually using a B-Tree), and slots it in perfectly. It’s neat, organized, and reliable. But what happens when you need...
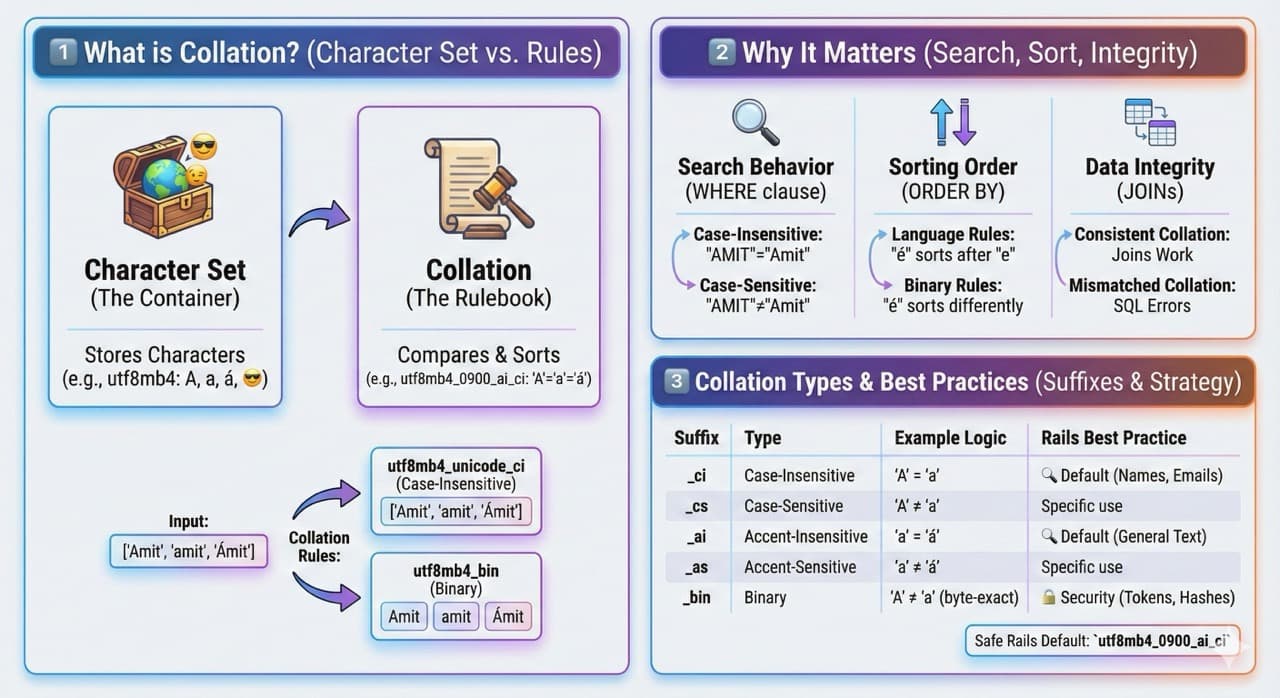
You've likely seen collation settings in your schema.rb or database.yml many times, but do you know exactly how they impact your application? In a standard Rails application, you might see this in a migration: add_column :users, :name, :string, colla...
ClearYourDoubt
5 posts
Today, I want to talk about something really cool: how Apache Lucene stores and retrieves data so efficiently.
We're not diving into Elasticsearch (it's built on top of Apache Lucene) but into the magic that makes Lucene so powerful for full-text search.
Let's say you're building an app where users search for courses like "Ruby on Rails" or "Java," and you need to return matching results fast. Sounds simple, right?
But when you look under the hood, it's not that straightforward. Let's explore why traditional databases fall short and how Lucene solves the problem.
Okay, let's talk about SQL databases like MySQL. They're great for structured data, but they kind of struggle when it comes to searching text.
Why? Because SQL stores data in tables and uses something called B+tree indexes to speed things up.
Now, B+trees are cool—they organize data hierarchically so you can look stuff up faster. But when it comes to searching through a lot of text, they aren't up to the task.
Imagine you run this query:
SELECT * FROM courses WHERE description LIKE '%microservice%';
Here's what happens:
SQL has to check every row in the table for the word "microservice."
If you've got thousands (or millions!) of rows, this is like asking someone to flip through a book page by page looking for one word. Painful, right?
On top of that, if you've got n rows and m characters in course, the time complexity can shoot up to O(N×M²); that's not good.
Now imagine you're running something huge like LinkedIn. If users are searching for stuff and your database is doing this kind of heavy lifting every time, it's only a matter of time before everything slows down—or worse, crashes.
Clearly, SQL isn't built for this kind of work.
So, maybe you're thinking, "What about NoSQL? Isn't it made for scaling?" Well, yes and no.
Key-value stores like Redis are great for quick lookups, but if you want to search text, you still need to scan every row for matches.
Document stores like MongoDB do better, but even they aren't optimized for advanced text search.
Bottom line? Neither SQL nor NoSQL gives you the speed and precision you need for full-text search.
Now here's where things get interesting. Instead of trying to force traditional databases to do something they're not built for, Lucene takes a completely different approach. It uses something called an inverted index.
Before diving into the explanation, let me ask you a question:
What data structure could we use to solve this problem? Two possibilities are a HashMap and a Trie.
However, there's a catch. If we use a HashMap as the data structure, the key would be the record ID/document ID, and the value would contain all the words present in that record or document. Sounds reasonable, right? But let's see how that works in practice.
Here's how data might look if stored in a traditional HashMap-like structure:
documents = {
1 => ["Ruby", "Programming", "Beginners", "Learning"],
2 => ["Java", "Advanced", "OOP"],
3 => ["Python", "Data", "Science"]
}
If you wanted to search for "Ruby," you'd have to go through each record to find where it appears. Slow, right?
Instead of storing records as keys and their words as values, we can flip the structure. This gives us something called an Inverted Index.
Here's how the data would look in an inverted index:
inverted_index = {
"ruby" => [1],
"programming" => [1],
"beginners" => [1],
"learning" => [1],
"java" => [2],
"advanced" => [2],
"oop" => [2],
"python" => [3],
"data" => [3],
"science" => [3]
}
With this structure, searching for "Ruby" takes you straight to document ID 1. No more flipping through pages—just instant results!
Keys: The words (terms) from your dataset.
Values: Lists of document IDs where those words appear.
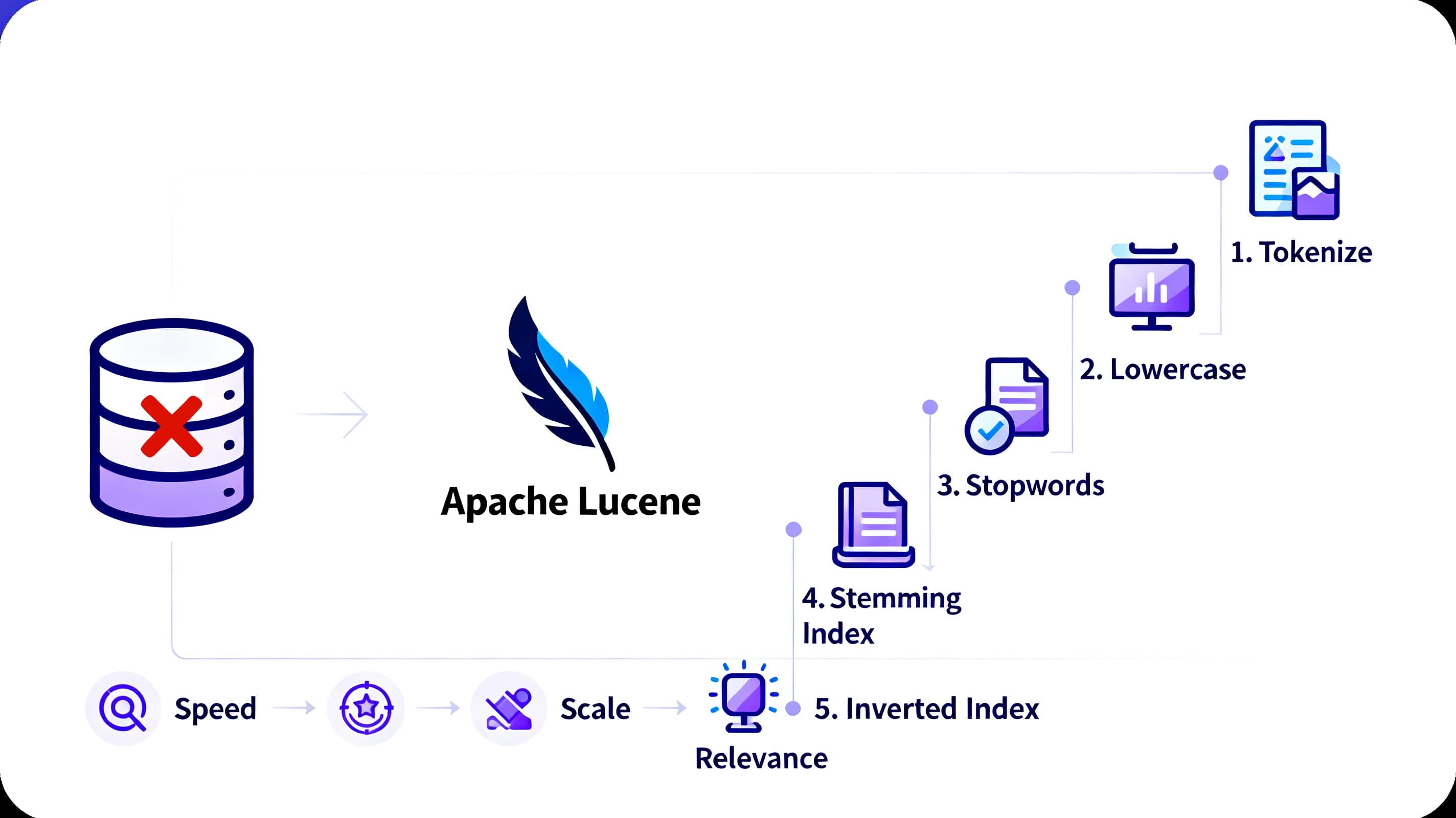
Lucene doesn't just use an inverted index—it improves it with extra steps to make searching even faster and more accurate.
First, Lucene takes the text and splits it into individual words, or tokens. For example:
Input: "Learn Ruby programming for beginners."
Tokens: ["Learn", "Ruby", "programming", "for", "beginners"]
Next, all tokens are converted to lowercase. This way, "Ruby" and "ruby" are treated the same.
Common words like "for," "a," or "the" are removed. These words don't add much meaning to searches, so Lucene skips them.
Lucene reduces words to their root form (this is called stemming). For example:
"learn" and "learning" → "learn"
"programming" and "programs" → "program"
Now, we've got: ["learn", "ruby", "program", "beginner"]
Finally, Lucene maps these tokens to the inverted index.
Each token becomes a key in the index.
Each key points to a list of documents (and positions) where the word appears.
inverted_index = {
"learn" => [{ doc: 1, positions: [0] }],
"ruby" => [{ doc: 1, positions: [1] }],
"program" => [{ doc: 1, positions: [2] }],
"beginner" => [{ doc: 1, positions: [3] }]
}
Now, if you search for "Ruby," Lucene can instantly tell you it's in document 1. Easy, right?
So why does Lucene beat traditional databases for full-text search?
Speed - With the inverted index, Lucene doesn't need to scan entire datasets. It goes straight to the relevant documents.
Ranking and Scoring - Lucene doesn't just find matches—it ranks them by relevance. It uses various algorithms.
Scalability - Lucene powers systems like Elasticsearch, OpenSearch, MongoDB Atlas, Solr, etc. that handle billions of documents.
Customizability - You can tweak Lucene to fit your needs—custom tokenizers, stop-word lists, analyzers, etc.
You're right—MySQL does support full-text search using inverted indexes. But here's the thing:
It's not as fast or scalable as Lucene.
It doesn't have advanced ranking features like TF-IDF or BM25.
It's harder to customise for specific use cases.
For more, check out MySQL's Full-Text Search Docs.
So, here's the takeaway:
SQL and NoSQL databases are great, but they're not built for full-text search.
Lucene's inverted index makes searching lightning-fast by flipping how data is stored.
It takes things even further with features like stemming, tokenization, and ranking.
That's why tools like Elasticsearch (which is built on Lucene) are so popular. They take Lucene's speed and scalability and make it even easier to use.
